Coping Noisy Annotations in Object Detection with Repeated Labels
The Evaluation Server can be found on EvalAI
This article gives a quick overview of my colleagues and my publication presented at the GCPR 2023 in Heidelberg.
Human Label Variation in Computer Vision
When data is labeled or annotated for computer vision tasks, inconsistencies can arise between different labelers. These inconsistencies can stem from:
- Differences in interpretation due to ambiguity.
- Genuine mistakes or errors.
- Various other factors.
Specifically, in tasks like object detection and instance segmentation, inconsistencies often manifest in three ways:
- Mismatched class assignments.
- Imperfect boundary outlining.
- Overlooked instances.
These inconsistencies can be thought of as “noise” since the mapping from visual features to labels isn’t unique. Since humans are the source of this inconsistency, it’s termed “human label variation” (B. Plank, 2022).
While training deep neural networks with such “noisy” annotations is a challenge in itself, evaluating them using standard metrics like Average Precision is not straightforward. To address this, one can either consolidate the annotations (aggregating) or sift through and select the most reliable ones (filtering). The approach discussed in the referenced paper leans towards consolidating or aggregating these annotations.
Aggregating object detection and instance segmentation annotations
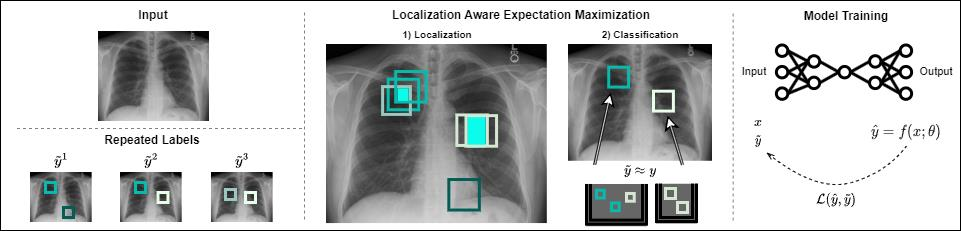
The aggregation process mentioned earlier is a two-step approach: first, there’s a voting mechanism, and based on the results of this voting, overlapping regions are merged. This results in a new approximation of the ground truth, which can be utilized for both training and testing purposes. For an in-depth look, please refer to the publication.
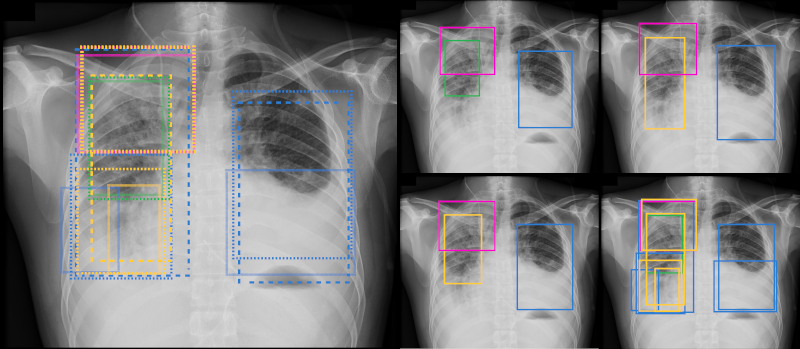
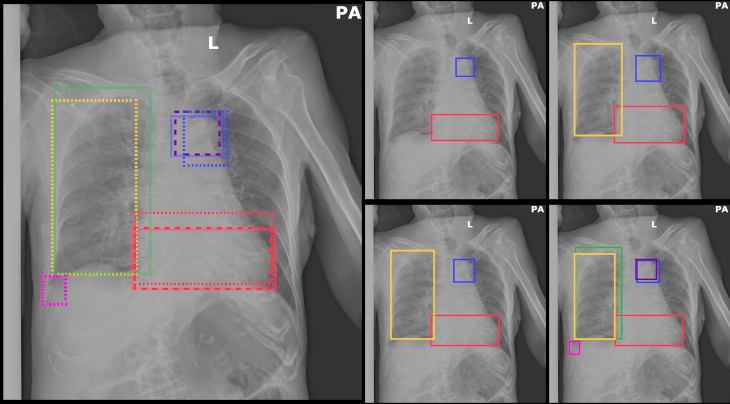
Annotation budget study
Purpose of the Study:
We wanted to delve deep into the world of image annotations to understand the most efficient way to allocate resources. The question was straightforward: is it better to have multiple annotations for fewer images or a single annotation for many images, given a fixed budget?
What We Investigated:
We conducted two studies, examining different ‘annotation budgets’. An ‘annotation budget’ here refers to the total amount of images or instances that can be labeled, considering the constraints of the annotators’ available time. We looked at scenarios where:
- Only single annotations were available.
- There was a blend of single and repeated annotations.
- Annotations were mostly repeated, leading to significantly less training data.
Our Findings:
-
For the TexBiG dataset: We found a saturation point beyond which adding more data didn’t bring much improvement. This indicates the potential of multi-annotator learning to make the most out of repeated labels.
-
For the VinDr-CXR dataset: The results improved with a larger budget, suggesting that more annotations are beneficial, especially when dealing with noisy labels that don’t often agree.
-
Inclusion of Repeated Labels: Adding moderate repeated labels didn’t hurt performance. In fact, these labels not only bolster reliability but also support efficient use of multi-annotator learning methods. The effort to create these repeated labels doesn’t seem to cost much in terms of performance or resources.
-
Annotator Splits: Fragmenting the annotations among more splits might lead to lower performance. The effect becomes noticeable especially under tight annotation budgets. This hints at future research directions where determining optimal splits even before starting the annotation might be crucial.
Conclusion:
While multiple annotations aren’t always the answer, they can be especially useful when the budget is tight. However, knowing which scenarios will benefit most from repeated annotations remains a challenge.
For a comprehensive analysis and detailed results, please refer to our research paper.